Cross-tabulation of signs from 28 ancient scripts
Table 1 describes the 28 ancient scripts cross-tabulated in Table 2, irrespectively of the eventual pronunciation or meaning of the signs. The only criterion is the visual similarity of the glyphs. We know that the stance and orientation of the signs of early scripts were not fixed but depended on the direction of writing. Considering this fact and allowing for some minor scribe-dependent variation, I listed similar signs from various scripts in rows. Occasionally, when signs presented various degrees of similarity, I inserted more than one line for the family with the most similar glyphs repeated in separate lines. I gave similar signs the numeric value 1, for simple existence within a script, and identical signs, the value 2. The last column of Table 2, called POP for popularity, gives the sum of the values in a line. Popularity is the number of scripts using a sign. If two or more scripts use the exact same sign, with value 2, the popularity of the sign is thus weighted compared to signs with simply similar versions used in the same number of scripts. For some tests (e.g., chi-square and other non-parametric tests), the entire table takes the values 1 for existence (independently of how similar the signs may look) and 0 for the non-existence of a sign in a script.
Alphabets typically have less
than 50 signs. Sets with 50-150 signs are usually classified as syllabic
scripts (syllabaries), even those that are admittedly not deciphered. Hieroglyphic
systems consist of many more signs, pictograms, ideograms, or
logograms with a semantic value but no phonetic value. This kind of
syllogism and arithmetic is relatively weak. It makes a western computer keyboard
with about 100 keys a syllabic writing tool. Linear B, for example, was given
12 consonants, 5 vowels, and 73-78 syllabic values. All the deciphered signs of
Linear B are taken from and are identical to Linear A signs
The similarity between glyphs is
challenging to quantify. Some scribes may use distinct strokes, while others would
join strokes into fewer curves. How much variation in curvature, angle width,
inclination, number, or length of strokes is phonetically and semantically
relevant, and how much of it is used for emphasis (e.g., uppercase, lowercase,
tonic accent, etc.), punctuation, declination, diacritics, prepositions, particles, other morphemes, or is just random? Fig. 1 shows the progressive abstraction of a Cretan
hieroglyphic sign from a pictographic form evoking a funnel-like dispenser with
a faucet to a simple K-like letter form. All these, and many more attested intermediate
forms, are variants of the same sign


Figure 2. Specimens of various Linear A sign classes from Salgarella & Castellan (2021). Columns represent different sign families and rows, specimens that may be confused.
We have the same difficulties
when comparing signs between scripts from different geographical regions and
times. In Fig. 3, sign 1 is the variant ZA-9
of the Linear A and B sign SigLA
AB65 found at Zakros, Crete. Morphologically, this sign correlates very poorly
with other members of its family.
Instead, it may be considered as a cursive variant of the family of signs SigLA
AB09, with mostly angular members, of which upright and rotated examples
are shown in positions 2 and 3. When rotated or flipped, sign 1 produces the
forms at positions 4-6. Form 4 is identical to sign 7 found in several Byblos
inscriptions
{kind=link}
{kind=link}
{kind=link}
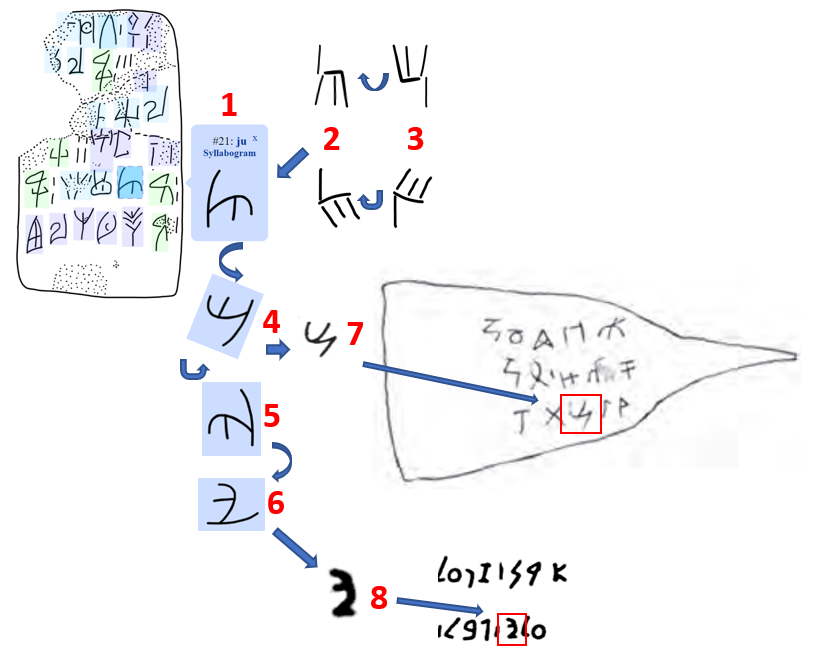
Figure 3. Examples of glyph variation between scripts showing the forms of a sign in Linear A (from Salgarella & Castellan, 2021; 1), the Byblos script (from Dunand, 1945, Fig. 27b; 7), and the Phoenician alphabet (Ahiram sarcophagus inscription; 8). The curved arrows indicate a rotation or flipping.
Table 2 may be used to measure similarity between scripts and testing hypotheses as to their provenance and relationships. We may test whether the Egyptian linear signs descend from the much older Armenian petroglyphs or the Balkan signs. The null hypothesis is that the Egyptian script is independent of the other two. Any resemblance is due to chance. Alternatively, knowing the Balcan or Armenian signs, we can predict the existence of corresponding signs in the Egyptian script. What proportion of our guesses would turn true? The following Chi-square test shows no association of the Egyptian linear signs with the Balkan script (p=0.153; any similarity can be attributed to chance) but a very significant association with the Armenian signs (p=7.9E-5; the null hypothesis is rejected).
|
|
|
Egyptian linear |
|
|
|
|
|
Exists |
no |
|
yes |
|
|
|
|
Count |
Row % |
Count |
Row % |
|
Balkan |
no |
263 |
84.6% |
48 |
15.4% |
|
|
yes |
118 |
79.2% |
31 |
20.8% |
|
Armenian |
no |
298 |
86.9% |
45 |
13.1% |
|
|
yes |
83 |
70.9% |
34 |
29.1% |
|
Pearson Chi-Square Tests |
|
|
|
|
|
Egyptian linear |
|
Balkan |
Chi-square |
2.043 |
|
|
Sig. |
.153 |
|
Armenian |
Chi-square |
15.584 |
|
|
Sig. |
7.9E-5* |
Results are based on nonempty rows and columns in each innermost subtable. *The Chi-square statistic is significant at the 7.9e-5 level.
We have thus left with the alternative to the null hypothesis that the similarity between the Egyptian and Armenian scripts is not coincidental. There must be a reason other than chance (e.g., learning) to explain that nearly 30% of the Egyptian linear signs also exist among the much older Armenian petroglyphs.
Instead of comparing only two scripts at a time, we can use the ROC curves method to compare a target script to numerous others. We can thus measure the relative contribution of pre-existing scripts to the target script and evaluate the hypothesis of a pure coincidence for each presumed contributor. For example, did any Armenian, Balkan, Egyptian, Cretan hieroglyphic, Cypro-Minoan, or Proto-Sinaitic scripts significantly influence Linear A, and how much? This test plots the true positive rate (Sensitivity) over the false positive rate (1-Specificity) for each predictor. The further away the curve departs from the diagonal towards the upper-left corner, the better the predictor is.
Fig. 4 shows the results for the above question. Linear A is mainly influenced by the Balkan script (p=5.6e-3), but it also significantly resembles Armenian and Proto-Sinaitic (p<0.05). Surprisingly, it seems independent from Cretan hieroglyphs. Any similarities between these two Cretan scripts are due to chance or random archeological artifacts.
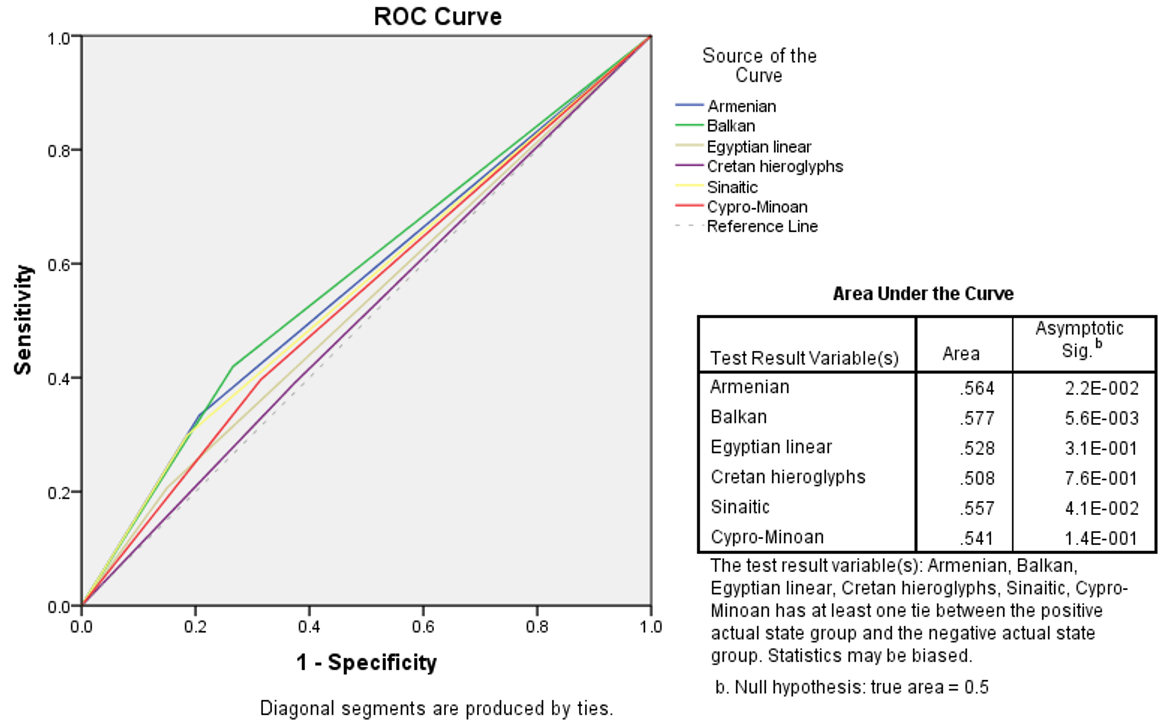
Figure 4. ROC curves comparing various older or co-existing scripts as progenitors of Linear A.
For securely dated scripts, we can tell which is the progenitor and which is the progeny. Linear A cannot have influenced the Balkan script because the latter is much older. Only the opposite proposition makes sense. With the Sinaitic script being approximately contemporary to Linear A, the resulting significant similarity may be interpreted in either direction. The above model measures how much the Sinaitic script, among others, has influenced Linear A. We may invert the model and ask how much Linear A has influenced the Sinaitic script. The results in Fig. 5 suggest that the Linear A > Sinaitic hypothesis (p=0.018) fits the data better than the Sinaitic > Linear A model (p=0.041). More precisely, the two scripts appear to have different origins, the Sinaitic being an Armenian-born script (p=1.2e-6) while Linear A is more of a Balkan script (p=5.6e-3).

Figure 5. ROC curves comparing Linear A and various older or co-existing scripts as progenitors of the Proto-Sinaitic scripts.
The ROC-curves method puts numbers to an obvious syllogism. Suppose you find 22 different objects in my house and the same items in a large supermarket among hundreds of other objects. the assumption that the supermarket purchases its products from my house is awkward; rather, I buy my provisions from the supermarket. A large set of distinct characters, like the Linear A script, cannot derive from a small subset, such as the Proto-Sinaitic script. The small subset more likely derives from a larger set.
References
Barthélémy, J.-J. (1764). Réflexions sur quelques monumens phéniciens et sur les alphabets qui en résultent. Histoire de l’Académie Royale Des Inscriptions et Belles-Lettres, 30, 405.
Table 1: Description of the scripts cross-tabulated in Table 2.
|
Call |
Full name of the script |
Proposed language |
Attestation region |
Earliest |
|
ARM |
not a
language |
Armenia |
7000 BC |
|
|
BAL |
not a
language |
Balkan Peninsula |
6000 BC |
|
|
EGY |
Egyptian (linear signs only) |
Egyptian |
Egypt |
3000 BC |
|
CHI |
unknown
language |
Crete |
2100 BC |
|
|
LIA |
unknown
language |
Crete, Aegean, Anatolia |
1800 BC |
|
|
LIB |
Greek |
Crete and
mainland Greece |
1450 BC |
|
|
CYM |
Cypro-Minoan
and Cypriot |
Greek |
Cyprus |
1550 BC |
|
SIN |
West Semitic |
Sinai
Peninsula and Egypt |
1900 BC |
|
|
CAN |
West Semitic |
Canaan |
1800 BC |
|
|
BYB |
Unknown
language |
Byblos |
1800 BC |
|
|
PHO |
West Semitic |
Mediterranean (mainly western) |
1050 BC |
|
|
GRE |
Archaic Greek (pooled) |
Greek |
Aegean and mainland Greece |
750 BC |
|
LYD |
Luwian-related
(IE) |
Western
Anatolia |
700 BC |
|
|
LYC |
Luwian-related
(IE) |
Western
Anatolia |
500 BC |
|
|
PHR |
Greek-related
(IE) |
Central
Anatolia |
800 BC |
|
|
CAR |
Greek-related |
South-West
Anatolia |
700 BC |
|
|
PAM |
Greek |
South
Anatolia |
500 BC |
|
|
MON |
Turkic |
Mongolia |
700 AD |
|
|
SAR |
South Semitic |
South Arabian
Peninsula |
800 BC |
|
|
ETR |
Old Italic |
Central Italy |
700 BC |
|
|
LEP |
Old Italic/Celtic |
Northern Italy |
550 BC |
|
|
NUC |
Old Italic |
Southern Italy |
600 BC |
|
|
OSC |
Old Italic |
Southern
Italy |
500 BC |
|
|
CAM |
Old Italic/Germanic |
Northern
Italy |
500 BC |
|
|
RHA |
Old Italic/Etruscan |
Northern
Italy |
500 BC |
|
|
VEN |
Old
Italic/Germanic |
Northern
Italy |
600 BC |
|
|
RUN |
Germanic |
Central
Europe |
150 AD |
|
|
GLA |
Slavic |
Central and
East Europe |
800 AD |





