Letter usage in English, French, Latin, Greek, and epic poetry.
To get an idea of the difference in the frequency in which European languages and authors use their letters, I performed a principal components (PC) analysis
This trivial variation is taken into account and measured by the first PC (PC1). There is, however, variation in letter usage that is specific to a linguistic group or to a language. Obviously, the Latin and Greek alphabets are not identical. Some Greek letters are absent from Latin and vice versa. Even letters and clusters that exist in all languages within a group may present significantly different frequencies of usage. For example, K and Ck are quite frequent in English, rare in French (they use Qu instead), and hardly ever seen in Latin. The morphemes of each language, e.g. the English past -ed and gerund -ing endings, cause their respective letters to increase in usage within that language. Such language-specific or, even, text-specific variation is quantified by the subsequent principal components, PC2, PC3, etc., which are numbered by the decreasing amount of variance they explain (labeled as Dimension 1-8).
I measured the frequencies of single letters and 2 or 3-letter clusters in lexica
Table 1. Lexica and number of words used in the principal components analysis of letter usage frequencies.
|
Lexicon |
Words |
|
English |
40480 |
|
French |
46898 |
|
Latin |
16969 |
|
Ancient Greek |
36486 |
|
Modern Greek |
35282 |
|
Iliad |
19245 |
|
Odyssey |
15456 |
|
Theogony |
2848 |
|
Works and Days |
2618 |
|
|



Table 2. Principal
components of letter and letter-cluster frequencies.
|
Dimension |
Eigenvalue |
Variance (%) |
Cumulative variance (%) |
|
Dim.1 |
8.401 |
93.34 |
93.345 |
|
Dim.2 |
0.320 |
3.56 |
96.900 |
|
Dim.3 |
0.170 |
1.88 |
98.785 |
|
Dim.4 |
0.058 |
0.65 |
99.432 |
|
Dim.5 |
0.027 |
0.30 |
99.732 |
|
Dim.6 |
0.014 |
0.16 |
99.889 |
|
Dim.7 |
0.006 |
0.06 |
99.953 |
|
Dim.8 |
0.004 |
0.04 |
99.995 |
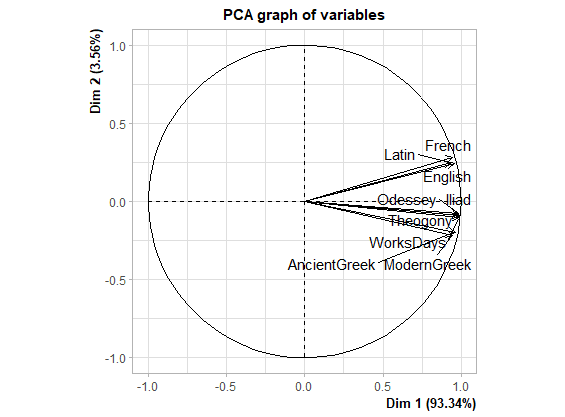

Figure 5. Biplot of principal components 1 and 2 of letter and cluster usage frequencies showing the most influential letters or clusters.

Figure 6. Biplot of principal components 3 and 4 of letter and cluster usage frequencies showing the most influential letters or clusters.

Figure 7. Biplot of principal components 5 and 6 of letter and cluster usage frequencies showing the most influential letters or clusters.

Figure 8. Biplot of principal components 7 and 8 of letter and cluster usage frequencies showing the most influential letters or clusters.
References
Gregory R. Crane (ed.). (2012). Open Source Code. Perseus Digital Library.
Kassambara, A. (2017). PCA - Principal Component Analysis Essentials. STHDA.
Kyparissiadis, A. (n.d.). GreekLex: A lexical database of Modern Greek. Retrieved March 13, 2022,
Kyparissiadis, A., van Heuven, W. J. B., Pitchford, N. J., & Ledgeway, T. (2017). GreekLex 2: A comprehensive lexical database with part-of-speech, syllabic, phonological, and stress information. PLoS ONE, 12(2).
Liddell, H. G., & Scott, R. (1996). A Greek-English Lexicon (H. S. Jones & R. McKenzie, Eds.; 9th ed.). Oxford University Press.
New, B., & Pallier, C. (2017). Lexique version 3.82. Lexique.Org.